yacc 语法规范(bison)
- 整体结构
/P1: declarations 定义段/
%{%}
%%
/P2: grammar rules 规则段(rule-action)/A: a1 { 语义动作1 }
| a2 { 语义动作2 }
| …
| an { 语义动作n }
| b //没有{…},则使用缺省的语义动作
; //产生式结束标记
//语义动作一般是在产生式右部分析完,归约动作进行前执行。
A→ a1 | a2 | … | an | b
%%/* P3: supporting C routines 用户辅助程序段(C函数) */
- 符号
由词法分析器产生的符号称为终结符或者token。
在规则左侧定义的的符号称为非终结符。
定义部分
- %{ %}之间定义的文字块,通常被原样拷贝到代码中。
- 声明部分
- %start
- 起始规则,即语法分析器首先分析的规则。默认是第一条规则,如果希望其他规则作为起始规则,需要增加声明:%start somename
- %token
- 也可以叫终结符,是词法分析器传递给语法分析器的符号。
语法分析器调用yylex()获取下一个token。
- %left、%right、%nonassoc:
- 定义了运算符的结合性,同一行的运算符优先级相同,不同行的运算符,后定义的行具有更高的优先级。
- %type
- 使用%type来声明非终结符。
- %type的名字必须以%union定义过。
- %union
- %union声明标示了符号值所有的变量类型。
- %union声明将原样拷贝到以YYSTYPE为类型的C的union声明中。
- 如果不存在%union声明,yacc将把YYSTYPE定义为int,这样所有的符号值都是int。
- %type把%union中声明的类型与特定的符号关联起来。
总结
%token 定义文法中使用了哪些终结符。定义形式: %token TOKEN1 TOKEN2
终结符一般全大写;(如 TOKEN1 TOKEN2)
一行可定义多个终结符,空格分隔;%left、%right、%nonassoc 也是定义文法中使用了哪些终结符。定义形式与%token类似。
先定义的优先级低,最后定义的优先级最高,同时定义的优先级想通过。
%left表示左结合,%right表示右结合;
%nonassoc 表示不可结合(即它定义的终结符不能连续出现。例如<,如果文法中不允许出现形如a<b<c的句子,则<就是不可结合的)%left AA BB
%nonassoc CC
%right DD
表示优先级关系为:AA=BB<CC<DD,表示结核性为:AA\BB左结合, DD右结合, CC不可结合。
注意:也可以于%prec来结合使用来改变token的优先级和结合性 例如: :'-' expr %prec NEG { $$ = -$2; };%union 声明语法符号的语义值类型的集合,
bison中每个符号包括记号和非终结符都有一个不同数据类型的语义值,并使用yylval变量在移进和归约中传递这些值,YYSTYPE(宏定义)为yylval的类型,默认为int;
我们使用%union来重新定义符号的类型
%union
{
int iValue; /* integer value /
char sIndex; / symbol table index /
nodeType nPtr; /* node pointer */
};%type 定义非终结符其属性值的类型。
%type sym1 sym2
%typesym3 %start 指定文法的开始的文法符号(非终结符),是最终需要规约而成的符号。
定义形式为:%start startsym , 其中startsym为文法的开始符号。
如果不使用%start定义文法开始符号,则默认在第二部分规则段中定义的第一条生产式规则的左部非终结符为开始符号。
- 规则部分 由rule(语法规则)和action(包括C代码)组成。
- 规则中目标或非终端符放在左边,后跟一个冒号:然后是产生式的右边,之后是对应的动作(用{}包含)。动作即yacc匹配语法中的一条规则时之行的代码。例如:date: month '/' day '/' year { $$ = sprintf("date %d-%d-%d", $1, $3, $5); }
%%
program: program expr '\n' { printf("%d\n", $2); }
;expr: INTEGER {$$ = $1; } | expr '+' expr { $$ = $1 + $3; }
| expr '-' expr { $$ = $1 - $3}
;
%%
注意:$1表示右边的第一个标记的值,$2表示右边的第二个标记的值,依次类推。$$表示归约后的值。
用户子程序 原样被拷贝到C文件的代码片段。
移进/归约
- 移进(shift):语法分析器读取token时,当读取的token无法匹配一条规则时,则将其压入一个内部堆栈(union为压入堆栈的结构体),然后切换到一个新的状态,这个新的状态能够反映出刚刚读取的token。
- 归约(reduction):当发现压入的token已经能够匹配规则时,则把匹配的符号从堆栈中取出,然后将左侧符号压入堆栈。
例如,fred = 12 + 13的处理过程:
// 规则
statement: NAME '=' expression
expression: NUMBER + NUMBER
// 处理过程
fred
fred =
fred = 12
fred = 12 +
fred = 12 + 13 //匹配expression: NUMBER + NUMBER,可以归约
fred = expression //匹配statement: NAME '=' expression
statement
但是如果引入乘法后,可能会产生冲突,造成如下不同的语法结构。
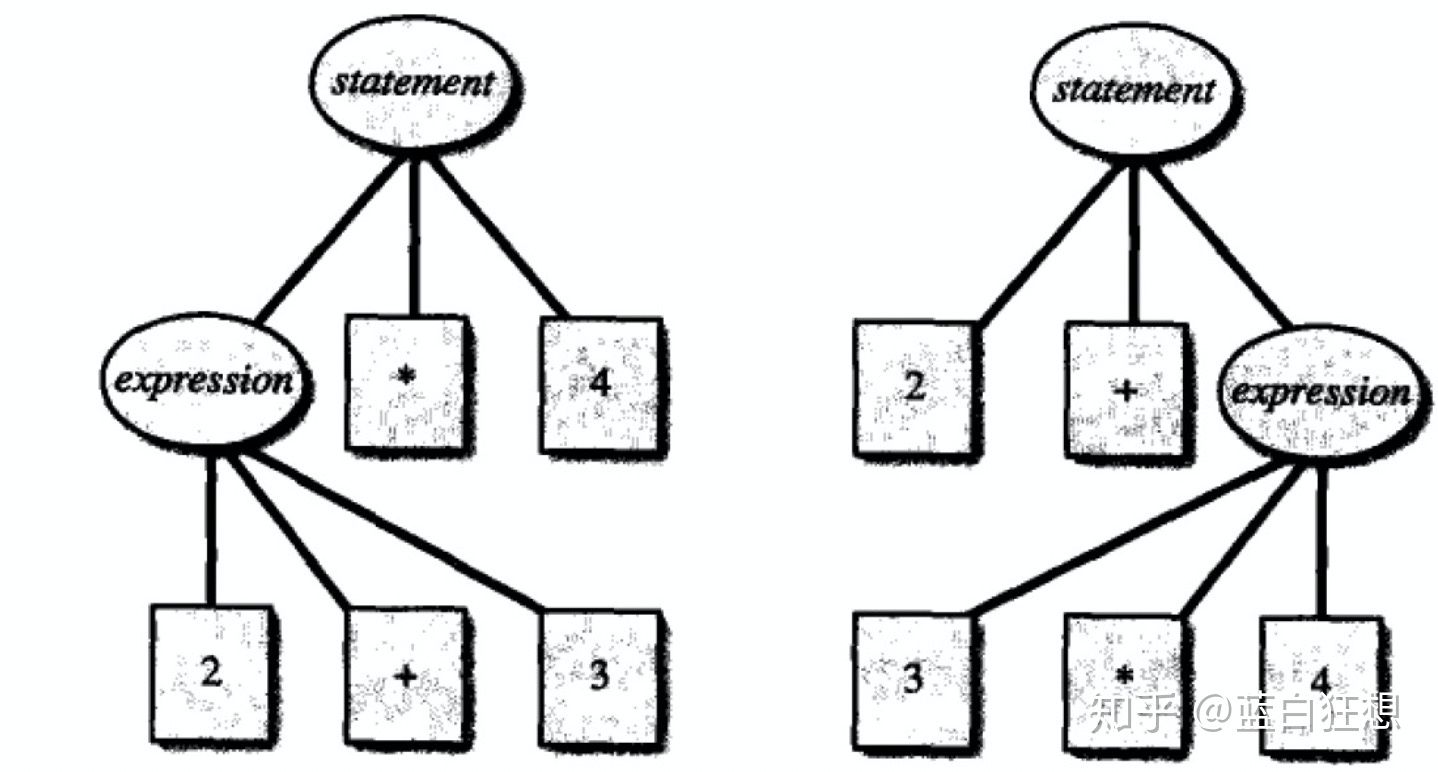
对于这种情况需要显示指定优先级和结合性来解决冲突:
- 优先级:决定了那个操作符先执行。例如,乘除法的优先级高于加减法。
- 结合性:表示具有相同优先级的操作符的结合顺序。
- 自左向右: a-b-c等价于(a-b)-c。
- 自右向左:a=b=c等价于a=(b=c)。
// 意义:+ - * /都是左结合,* /的优先级高于+ -。
%left '+' '-'
%left '*' '/'
使用goyacc
- 表达语法
- 语法规则可以返回值和分配类型
- 编写代码返回值
- 写词法分析器
Goyacc几乎是原yacc的精确翻译,所以一些特质被继承了下来。例如,C程序只返回1个值:0表示成功,1表示失败。这意味着您需要一些笨拙的样板文件来给lexer赋值。
%{
package jsonparser
func setResult(l yyLexer, v Result) {
l.(*lex).result = v
}
%}
%union{
}
%start main
%%
main:
{
setResult(yylex, 0)
}
- 使用go generate来创建实际的解析器.go文件
//go:generate goyacc -l -o parser.go parser.y
- 如何解析电话号码区号由三部分组成:区号、第一部分、第二部分。
%token D
phone:
area part1 part2
| area '-' part1 '-' part2
area: D D D
part1: D D D
part2: D D D D
- 大写字母表示令牌
如何返回值
- 生成的解析器只是一个运行状态机的单个函数,并使用局部变量。
- 这些变量保存在Union数据结构中:
# 定义部分
%{
package jsonparser
func setResult(l yyLexer, v Result) {
l.(*lex).result = v
}
%}
%union{
result Result
part string
ch byte
}
%token <ch> D
%type <result> phone
%type <part> area part1 part2
%start main
%%
# 规则部分
main: phone
{
setResult(yylex, $1)
}
phone:
area part1 part2
{
$$ = Result{area: $1, part1: $2, part2: $3}
}
| area '-' part1 '-' part2
{
$$ = Result{area: $1, part1: $3, part2: $5}
}
area: D D D
{
$$ = cat($1, $2, $3)
}
part1: D D D
{
$$ = cat($1, $2, $3)
}
part2: D D D D
{
$$ = cat($1, $2, $3, $4)
}
Lexing(词法分析)
- 在词法分析过程中,有两件事同时发生
- 规则匹配时,返回的int值决定匹配哪些规则。
- 代码正在执行根据哪个规则匹配。结果值在您编写的代码中使用。
有时Lex可以将字节本身返回为int。YACC已经构建了预定的令牌,所以所有的前127个字节都保留,并且可以在没有告诉解析器返回它们的情况下退回
// Result is the type of the parser result
type Result struct {
area string
part1 string
part2 string
}
// 解析的总入口。输入电话号码,输出为Result的解析结果。
func Parse(input []byte) (Result, error) {
l := newLex(input)
_ = yyParse(l)
return l.result, l.err
}
// 手动定义词法解析器
type lex struct {
input *bytes.Buffer
result Result
err error
}
func newLex(input []byte) *lex {
return &lex{
input: bytes.NewBuffer(input),
}
}
// 词法分析器满足Lex接口。能够逐个读取token。
// 如果是有效的电话号码数字,返回D类型,并赋值lval.ch。
func (l *lex) Lex(lval *yySymType) int {
b := l.nextb()
if unicode.IsDigit(rune(b)) {
lval.ch = b
return D
}
return int(b)
}
func (l *lex) nextb() byte {
b, err := l.input.ReadByte()
if err != nil {
return 0
}
return b
}
// Error satisfies yyLexer.
func (l *lex) Error(s string) {
l.err = errors.New(s)
}
func cat(bytes ...byte) string {
var out string
for _, b := range bytes {
out += string(b)
}
return out
}
执行过程
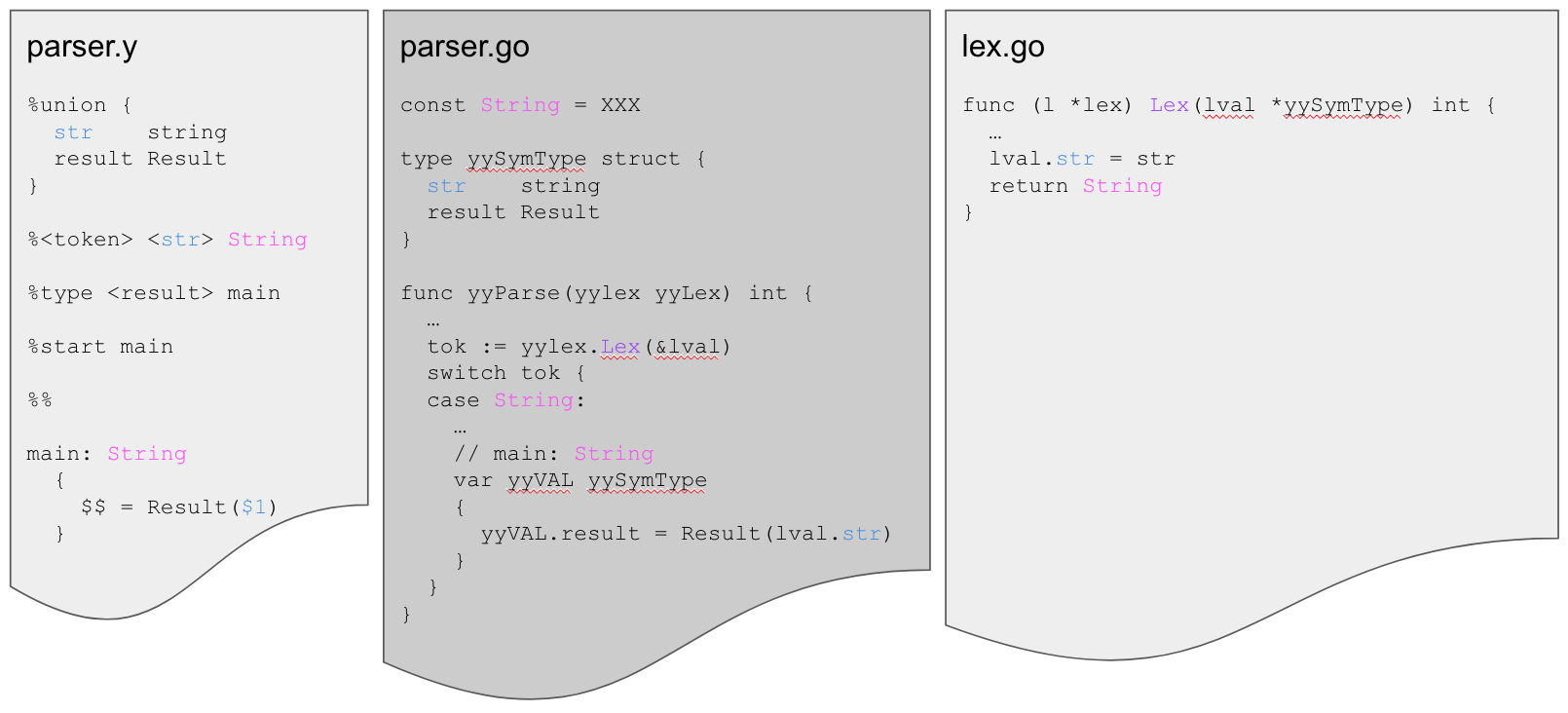
- Goyacc
- 为每个符号生成一个const字符串
- 为Lexer定义一个接口
- 定义一个接受lex作为输入的解析函数
lexing选项
- Rob Pike https://talks.golang.org/2011/lex.slide
- Fatih Arslan https://medium.com/@farslan/a-look-at-go-scanner-packages-11710c2655fc
- Use a ‘lex’ port
- go/scanner
- 手写
Lex跟日常代码不同,写一次会用很长时间。代码不整洁也可以。